
Web Scraping Success: Celebrating 100-Day Journey into Structured Coding and Data Analysis
Last week my webscraper completed its 100 days anniversary. I’ve been wanting to write about this project ever since I implemented it because this was the project that first put me to think about its structure rather than just write blocks and blocks of code.
I follow a lot of people from technology, and I’ve listened to lots of ideas regarding the mission to break into tech. One idea common to all of the people I follow is that you have to work on side projects. Even after getting in the field, you better still develop side projects. Building projects will put you in situations where you’ll really learn, and not only leave you reading tutorials on how to do this and that.
It took me a while to land with an idea of a side project.. I wanted to do something meaningful, at least for me. And the first spark came after watching a news story about food prices in Toronto, Canada - the city I live in for seven years now. (How to survive inflation (Marketplace) - YouTube ). Especially after covid, food prices rose all around the world like I haven’t seen before. And the news tells this story: how prices rise, and keep on rising, and how people in Toronto are dealing with it.
Back in Brazil we have an index for food prices, it’s called “Food Basket”, which takes into consideration the prices of 13 food products that are necessary to guarantee the substance of an adult worker. By the price of the basket you’ll have an idea of how much your groceries will be in a month, for example. I like it because it’s simple. No complex data or calculations, just plain and simple numbers. I do realize it might be a “too simple” way to analyze food prices, but I believe that people in general do not go through the hassle of checking every single food product to see how the price is behaving. In my opinion it’s better to have the information together in just one place, one number. That is it.
So there was the first spark for a side project. Let’s build something that shows the price of a Food Basket in Toronto. Easy peasy, right? No, not really. While I was watching the news on TV regarding the food prices in Toronto, I tried to find something online similar to the food basket we have in Brazil. But I couldn’t. I did find information regarding prices, but nothing clear about which food was included in such prices. And for me that information was crucial. I wanted to know, for example, how the price of meat has behaved in the last six months. Or how much was the price of cheese last year. I found out, though, that Canada has the National Nutritious Food Basket survey, which is a “tool used by various level of government and other stakeholders to monitor the cost of affordability of healthy eating. It “includes approximately 60 nutritious foods and their quantities for individuals in various age and sex groups” ( National nutritious food basket - Canada.ca ). I gotta say, what an amazing initiative. This is way beyond what I was expecting in terms of food price behavior. On top of the prices itself, it gives estimation of spending based on age groups. This is awesome!!! The only issue in my opinion is that the information is not widely publicized. They do not keep the outcomes of this survey online, at least I could not find it. What they have is an excel spreadsheet where you can go and fill it up by yourself. And here lies the justification for my side project: I wanted to develop a tool that gives information about food prices behavior in an easy and straightforward way.
Now, finally, let’s talk about the webscraper. Bear in mind this is a side project, I’m not an expert in data analysis, so the choices I’ve made in terms of collecting data were based on the difficulty, or not, to gather such information. Before we continue it’s important to highlight some points:
First, the data had to be collected online, and only. I needed to develop my skills with back-end development, so there was no point in going to stores by myself collecting prices.
Second, for the first version of this webscraper I’ve chosen to gather data from Nofrills grocery store. NoFrills is a Canadian chain of discount supermarkets with over 200 franchise stores located in nine Canadian provinces.
Third, if more than one option of an item is available I’m always choosing the cheapest one.
My only intention with this project is to develop my skills as a Software Developer, nothing else.
DATABASE The National Nutrition Food Basket contains a list of approximately 60 products. I went over the list, which is publicly provided, and chose 65 products and their cheapest options. I’ve separated them into six different departments: Meat, Produce, Frozen, Canned and Dry, Refrigerated and Bakery. This was necessary so I could create different collections in my MongoDB to better filter the data when needed. If this project was ever to evolve to something more scalable the differentiation of collections would also help with it.
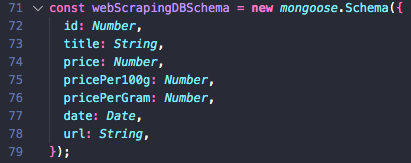
I could foresee from the beginning that I was going to need some information like the name of the product, price, price per 100g and price per g. So I’ve implemented my mongo schema as it follows:
WEBSCRAPER
Well, here is where the fun begins. I’ve built my webscraper using Puppeteer library, which provides a high-level API to control Chrome/Chromium over the DevTools Protocol. It runs headless. It also has the feature to use proxies, which I was going to need if I did not want my IP to eventually be blocked.
For the sake of this project I had to spend some time thinking in ways to avoid getting blocked by the supermarket website. I have never developed a webscraper before so I had to go out there and learn about it. Doing so I realized that my application could easily be blocked because of the amount of requests it was going to make through Puppeteer. Imagine that, scraping over 60 products everyday, with each product having six different information that needed to be grabbed from their website. I had to diminish the chances of getting blocked as much as I could. How did I do that? I made my code in a way that would imitate human behavior the best I could. Some points I considered while designing this webscraper:
IP rotation
In order to avoid my IP getting blocked I had to set up a proxy rotator. I realize the rotator I’ve come up with is not the most reliable one since it relies on public free proxies. I believe that paid services would provide me with more reliable sources, but I was not planning to spend real money on this project. At least for now.
Set random timeout intervals
It was crucial for my webscraper to work that it imitates human behavior. I couldn’t have over sixty functions running one on top of each other without any order, and/or with the same interval in between them. So I made use of setTimeOut functions for each of the items and on top of that implemented a function that would generate a random number to use as the interval itself. So instead of having all my functions running one after the other with an interval of 15 seconds, for example, I would still have them being called one after the other but in different intervals.For every product scraped a log with the time it happened is shown - this way I can compare the timing between all of my functions to make sure they’re following random intervals instead of fixed ones.
Debug-friendly
With the setTimeOut functions in place I went ahead and put all the functions that would extract information from the items in an async chain. I found that very useful because one thing I’ve noticed running the first tests is that the URL for the products get changed from time to time. Developing a chain of async functions and logging all the results help me debug the code whenever it tries to fetch an URL that no longer exists.
I will write more in the future about these three points, but for now I believe it is enough to understand the pillars of my application.
